
- Убедиться, что у Васи достаточно денег на счету
Нужно убедиться, что сумма доступна Васе для перевода. Необходимо получить значение текущего баланса пользователя, если оно меньше чем сумма, которую он хочет перевести — сказать ему об этом. С учетом того, что на нашем сайте не предусмотрены кредиты и в минус баланс уйти не должен.
- Вычесть сумму, которую необходимо перевести из баланса пользователя
Необходимо записать в значение баланса текущего пользователя его баланс с вычетом переводимой суммы. Было 100, стало 100-100=0.
- Добавить к балансу пользователя Петя сумму которую перевели.
Пете наоборот, было 0, стало 0+100=100.
- Вывести сообщение пользователю, что он молодец!
При написании программ человек берет простейшие алгоритмы, которые он объединяет в единый сюжет, что и будет являться сценарием программы. В нашем случае, задача программиста написать логику переводов денег (баллов, кредитов) от одного человека к другому в веб-приложении. Руководствуясь логикой можно составить алгоритм, состоящий из нескольких проверок. Представим, что мы просто убрали все лишнее и составили псевдокод.
Псевдокод
Если (Вася.баланс >= сумма_перевода) То Вася.Баланс=Вася.Баланс-сумма_перевода Петя.Баланс=Петя.Баланс+сумма_перевода Поздравление() Иначе Ошибка()
Но всё бы ничего, если бы все происходило в порядке очереди. Но сайт может обслуживать одновременно множество пользователей, а это происходит не в одном потоке, потому что современные веб-приложения используют многопроцессорность и многопоточность для параллельной обработки данных. C появлением многопоточности у программ появилась забавная архитектурная уязвимость — состояние гонки (или race condition).
А теперь представим, что наш алгоритм срабатывает одновременно 3 раза.
У Васи все так же 100 баллов на балансе, только вот каким-то образом он обратился к веб-приложению тремя потоками одновременно (с минимальным количеством времени между запросами). Все три потока проверяют, существует ли пользователь Петя, и проверяют, достаточно ли баланса у Васи для перевода. В тот момент времени, когда алгоритм проверяет баланс, он всё еще равен 100. Как только проверка пройдена, из текущего баланса 3 раза вычитается 100, и добавляется Пете.
Что мы имеем? У Васи на счету минусовой баланс (100 — 300 = -200 баллов). Тем временем, у Пети 300 баллов, хотя фактически, должно быть 100. Это и есть типичный пример эксплуатации состояния гонки. Сравнимо с тем, что по одному пропуску проходят сразу несколько человек. Ниже снимок экрана такой ситуации от @4lemon
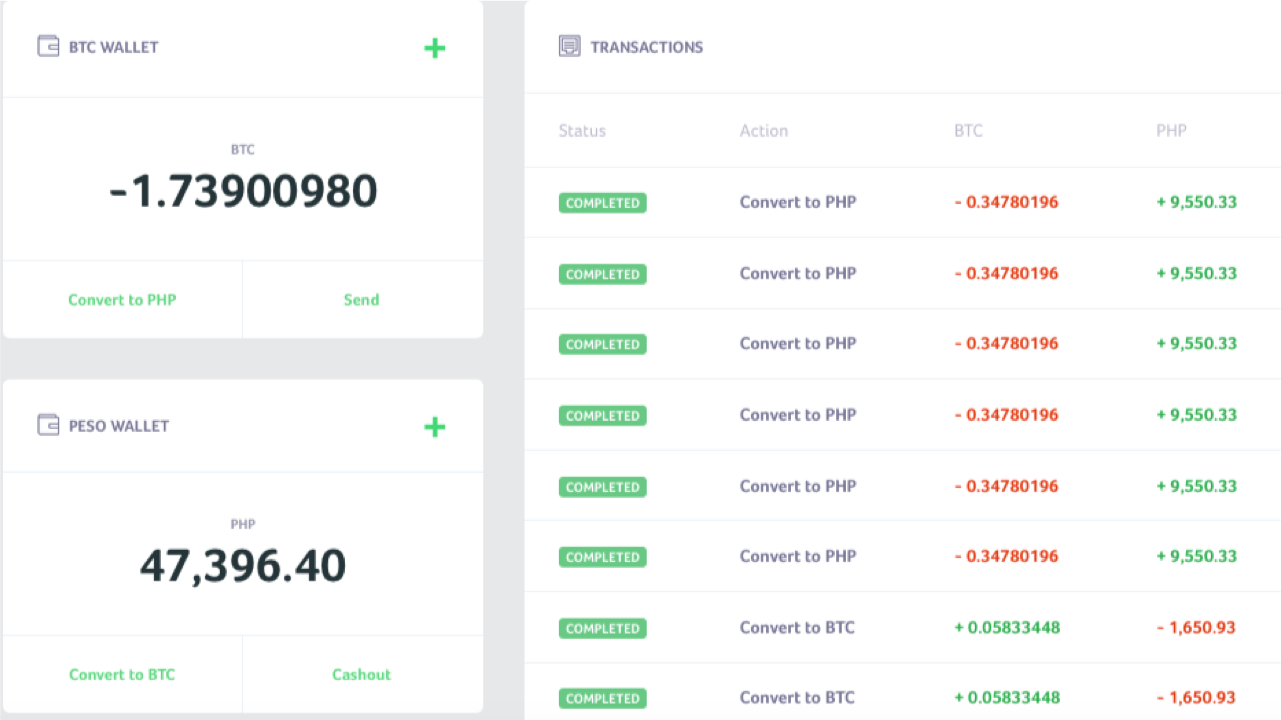
Состояние гонки может быть как в многопоточных приложениях, так и в базах данных, в которых они работают. Не обязательно в веб-приложениях, например, это частый критерий для повышения привилегий в операционных системах. Хотя веб-приложения имеют свои особенности для успешной эксплуатации, о которых я и хочу рассказать.
Типичная эксплуатация race condition
”Заходит хакер в кальянную, квест и бар, а ему — у вас race condition!
Омар Ганиев
В большинстве случаев для проверки/эксплуатации состояния гонки используют многопоточное программное обеспечение в качестве клиента. Например, Burp Suite и его инструмент Intruder. Ставят один HTTP-запрос на повторение, устанавливают много потоков и включают флуд. Как например, в этой статье. Или в этой. Это достаточно рабочий способ, если сервер допускает использование множества потоков на свой ресурс и как пишут в статьях выше — если не получилось, попробуйте ещё раз. Но дело в том, что в некоторых ситуациях, это может быть не эффективно. Особенно если вспомнить, как подобные приложения обращаются к серверу.
Что там на сервере
Каждый поток устанавливает TCP соединение, отправляет данные, ждет ответа, закрывает соединение, открывает снова, отправляет данные и так далее. На первый взгляд, все данные отправляются одновременно, но сами HTTP-запросы могут приходить не синхронно и в разнобой из-за особенностей транспортного уровня, необходимости устанавливать защищенное соединение (HTTPS) и резолвить DNS (не в случае с burp’ом) и множества слоёв абстракций, которые проходят данные до отправки в сетевое устройство. Когда речь идет о миллисекундах, это может сыграть ключевую роль.
Конвейерная обработка HTTP
Можно вспомнить о HTTP-Pipelining, в котором можно отправлять данные с помощью одного сокета. Ты можешь сам посмотреть как это работает, использовав утилиту netcat (у тебя же есть GNU/Linux, ведь так?).
На самом деле использовать linux необходимо по многим причинам, ведь там более современный стек TCP/IP, который поддерживается ядрами операционной системы. Сервер скорее всего тоже на нем.
Например, выполни команду nc google.com 80 и вставь туда строки
GET / HTTP/1.1 Host: google.com GET / HTTP/1.1 Host: google.com GET / HTTP/1.1 Host: google.com
Таким образом, в рамках одного соединения будет отправлено три HTTP-запроса, и ты получишь три HTTP ответа. Эту особенность можно использовать для минимизации времени между запросами.
Что там на сервере
Веб-сервер получит запросы последовательно (ключевое слово), и обработает ответы в порядке очереди. Эту особенность можно использовать для атаки в несколько шагов (когда необходимо последовательно выполнить два действия в минимальное количество времени) или, например, для замедления работы сервера в первом запросе, чтобы увеличить успешность атаки.
Трюк — ты можешь мешать серверу обработать твой запрос нагружая его СУБД, особенно эффективно если будет использован INSERT/UPDATE. Более тяжелые запросы могут “затормозить” твою нагрузку, тем самым, будет большая вероятность, что ты выиграешь эту гонку.
Разбиение HTTP-запроса на две части
Для начала вспомни как формируется HTTP-запрос.
Ну как ты знаешь, первая строка это метод, путь и версия протокола:
GET / HTTP/1.1
Дальше идут заголовки до переноса строки:
Host: google.com Cookie: a=1
Но как веб-сервер узнает, что HTTP-запрос закончился?
Давай рассмотрим на примере, введи nc google.com 80, а там
GET / HTTP/1.1 Host: google.com
после того, как нажмешь ENTER, ничего не произойдет. Нажмешь еще раз — увидишь ответ.
То есть, чтобы веб-сервер принял HTTP-запрос, необходимо два перевода строки. А корректный запрос выглядит так:
GET / HTTP/1.1\r\nHost: google.com\r\n\r\n
Если бы это был метод POST (не забываем про Content-Length), то корректный HTTP-запрос был бы таким:
POST / HTTP/1.1 Host: google.com Content-Length: 3 a=1
или
POST / HTTP/1.1\r\nHost: google.com\r\nContent-Length: 3\r\n\r\na=1
Попробуй отправить подобный запрос из командной строки:
echo -ne "GET / HTTP/1.1\r\nHost: google.com\r\n\r\n" | nc google.com 80
В итоге ты получишь ответ, так как наш HTTP-запрос полноценный. Но если ты уберешь последний символ \n, то ответа не получишь.
На самом деле многим веб-серверам достаточно использовать в качестве переноса \n, поэтому важно не менять местами \r и \n, иначе дальнейшие трюки могут не получиться.
Что это даёт? Ты можешь одновременно открыть множество соединений на ресурс, отправить 99% своего HTTP-запроса и оставив неотправленным последний байт. Сервер будет ждать пока ты не дошлёшь последний символ перевода строки. После того, как будет ясно, что основная часть данных отправлена — дослать последний байт (или несколько).
Это особенно важно, если речь идет о большом POST-запросе, например, когда необходима заливка файла. Но и даже в небольшом запросе это имеет смысл, так как доставить несколько байт намного быстрее, чем одновременно килобайты информации.
Задержка перед отправкой второй части запроса
По результатам исследования Влада Роскова, нужно не только расщеплять запрос, но и имеет смысл делать задержку в несколько секунд между отправкой основной части данных и завершающей. А всё потому, что веб-сервера начинают парсить запросы еще до того, как получат его целиком.
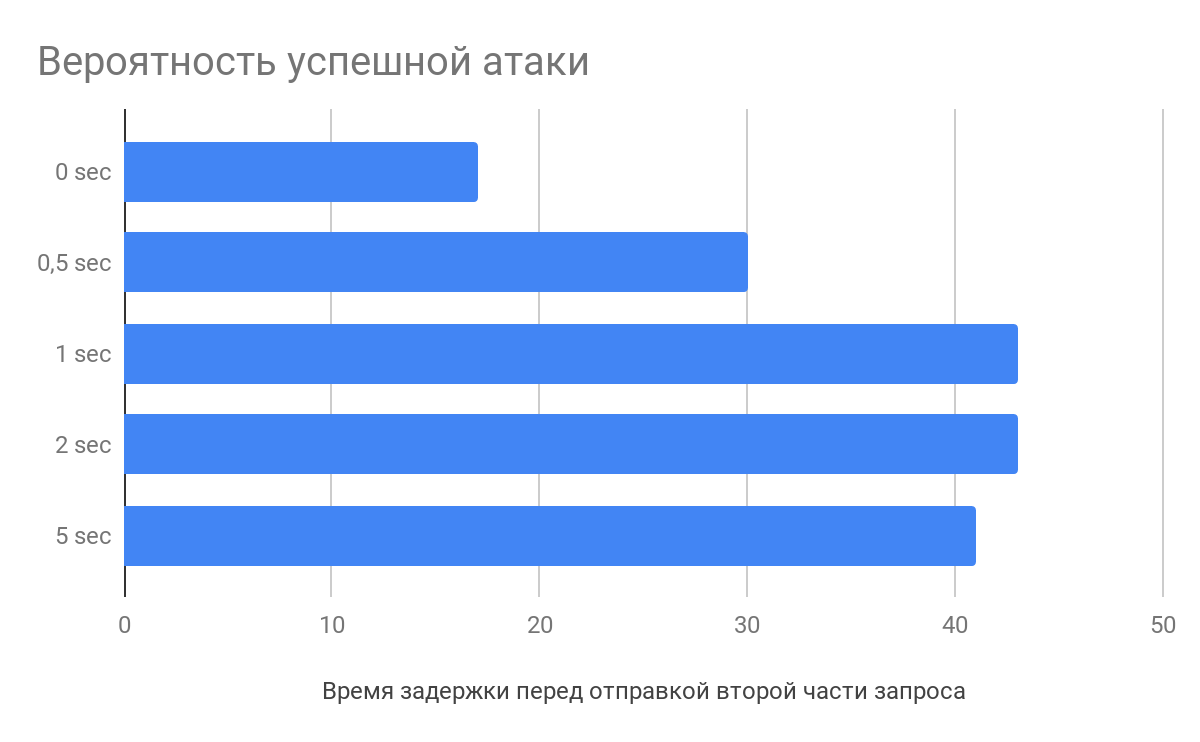
Что там на сервере
Например nginx при получении заголовков HTTP-запроса начнет их парсить, складывая неполноценный запрос в кэш. Когда придет последний байт — веб-сервер возьмет частично обработанный запрос и отправит его уже непосредственно приложению, тем самым сокращается время обработки запросов, что повышает вероятность атаки.
Как с этим бороться
В первую очередь это конечно же архитектурная проблема, если правильно спроектировать веб-приложение, можно избежать подобных гонок.
Обычно, применяют следующие методы борьбы с атакой:
- Используют блокировки.
Операция блокирует в СУБД обращения к заблокированному объекту, пока его не разблокируют. Другие стоят и ждут в сторонке. Необходимо правильно работать с блокировками, не блокировать ничего лишнего. - Рулят изоляциями транзакций.
Упорядоченные транзакции (serializable) — гарантируют, что транзакции будут выполнены строго последовательно, однако, это может сказаться на производительности. - Используют мьютексные семафоры (простихоспади).
Берут какую-нибудь штуку (например etcd). В момент вызова функций создают запись с ключом, если не получилось создать запись, значит она уже есть и тогда запрос прерывается. По окончании обработки запроса запись удаляется.
И вообще мне понравилось видео выступления Ивана Работяги про блокировки и транзакции, очень познавательно.
Особенности сессий в race condition
Одна из особенностей сессий может быть то, что она сама по-себе мешает эксплуатировать гонку. Например, в языке PHP после session_start() происходит блокировка сессионного файла, и его разблокировка наступит только по окончанию работы сценария (если не было вызова session_write_close). Если в этот момент вызван другой сценарий который использует сессию, он будет ждать.
Для обхода этой особенности можно использовать простой трюк — выполнить аутентификацию нужное количество раз. Если веб-приложение разрешает создавать множество сессий для одного пользователя, просто собираем все PHPSESSID и делаем каждому запросу свой идентификатор.
Близость к серверу
Если сайт, на котором необходимо эксплуатировать race condition хостится в AWS — возьми тачку в AWS. Если в DigitalOcean — бери там.
Когда задача отправить запросы и минимизировать промежуток отправки между ними, непосредственная близость к веб-серверу несомненно будет плюсом.
Ведь есть разница, когда ping к серверу 200 и 10 мс. А если повезет, вы вообще можете оказаться на одном физическом сервере, тогда зарейсить будет немного проще 🙂
Подводя черту
Для успешного race condition можно применять различные трюки для увеличения вероятности успеха. Отправлять несколько запросов (keep-alive) в одном, замедляя веб-сервер. Разбивать запрос на несколько частей и создавать задержку перед отправкой. Уменьшать расстояние до сервера и количество абстракций до сетевого интерфейса.
В результате этого анализа мы вместе с Michail Badin разработали инструмент RacePWN
Он состоит из двух компонентов:
- Библиотеки librace на языке C, которая за минимальное время и используя большинство фишек из статьи отправляет множество HTTP-запросов на сервер
- Утилиты racepwn, которая принимает на вход json-конфигурацию и вообще рулит этой библиотекой
RacePWN можно интегрировать в другие утилиты (например в Burp Suite), или создать веб-интерфейс для управления рейсами (все никак руки не доходят). Enjoy!
Но на самом деле ещё есть куда расти и можно вспомнить о HTTP/2 и его перспективы для атаки. Но в данный момент HTTP/2 у большинство ресурсов лишь фронт, проксирующий запросы в старый-добрый HTTP/1.1.
Может ты знаешь еще какие-то тонкости?
Join the discussion 4 комментария