
What is happening inside? What does the programmer need to do for everything to work correctly?
1. Make sure that John has enough money in his account
The system needs to make sure that John has sufficient funds to transfer the required amount. It is necessary to get the value of his current balance; if it is less than the amount that he wants to transfer, notify him about it. We must bear in mind that our web service does not provide loans and the balance cannot go negative.
2. Subtract the amount to be transferred from the user’s balance
We should update the balance of the current user deducting the amount transferred. It was 100, it became 100-100 = 0.
3. Add to Peter’s balance the amount that was transferred
At the Peter’s side, it is the opposite: it was 0, it became 0+100 = 100.
4. Display a message to the user that everything is fine!
When writing programs, a person takes the simplest algorithms and then combines them into a single plot which will make the script of a new program. In our case, the programmer’s task is to write the logic of money transfers (points, credits) from one person to another in a web application.
Guided by logic, we can compose an algorithm consisting of several checks. Imagine that we just removed everything unnecessary and compiled a pseudocode.
Pseudocode
If (John.Balance >= transfer_amount) Then John.Balance = John.Balance - transfer_amount Peter.Balance = Peter.Balance + transfer_amount Congratulations () Else Error ()
And there would be no problems if everything happened in an orderly fashion. However, the site can serve many users at the same time, and this does not happen in one thread, because modern web applications use multiprocessing and multithreading to process data in parallel. With the introduction of multithreading, programs inherited a funny architectural vulnerability: the race condition.
Now imagine that our algorithm is triggered simultaneously 3 times.
John still has 100 points on his balance, but somehow he managed to make three requests to the web application in three threads at the same time (with a minimum amount of time between requests). All three threads check whether the user ‘Peter’ exists or not, and check if John has sufficient funds to transfer the required amount. At the moment when the algorithm checks the balance, it is still 100. As soon as the verification is completed, 100 is deducted 3 times from the current balance and added to the Peter’s account.
What is the result? John has a negative balance in his account (100-300 = -200 points). Meanwhile, Peter has 300 points, although it should be 100. This is a typical example of the race condition exploitation. It is akin to a situation when several people slip in using one ID card. Below is the screenshot of such a case from @4lemon
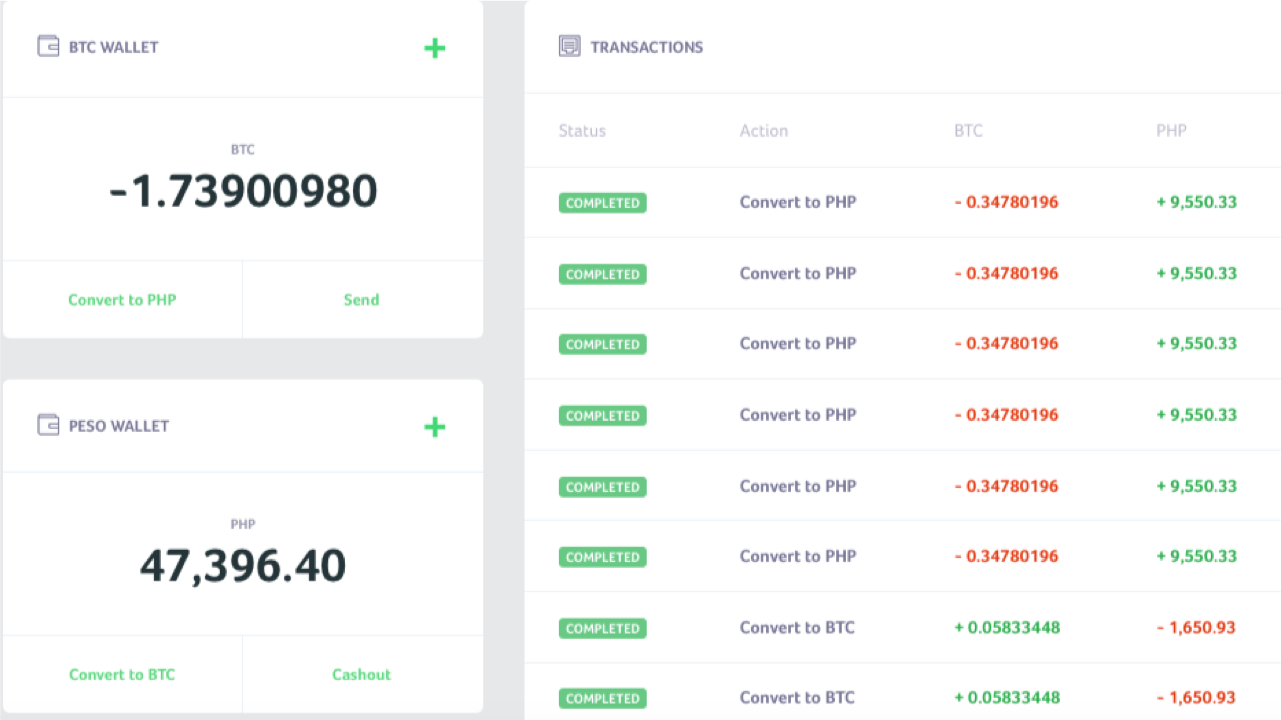
The race condition occurs both in multithreaded applications and in the databases in which they work. And it is not limited to web applications only. For example, this is a common criterion for privilege escalation in operating systems. Nevertheless, web applications have their own characteristics for successful exploitation, which I want to talk about.
Typical Race Condition Exploitation
”A hacker walks into a hookah lounge, an escape room, and a bar. The bartender says to him, “You have a race condition!”
Omar Ganiev
In most cases, multithreaded software is used as a client to check/exploit the race condition, e.g. Burp Suite and its Intruder tool. They put one HTTP request on repeat, create multiple threads, and start flooding. Like, for example, in this article. Or in this one. This is a fairly working way if the server allows the use of multiple threads to its resource, and as the articles above say: if it didn’t work, try again. But the fact is that in some cases this may not be effective. Especially if we think back to how such applications access the server.
What’s on the server side
Each thread establishes a TCP connection, sends data, waits for a response, closes the connection, opens it again, sends data, and so on. At first glance, all data is sent at the same time, but HTTP requests themselves may not arrive synchronously due to the nature of the transport layer, the need to establish a secure connection (HTTPS) and resolve DNS (not in the case of Burp), as well as due to many layers of abstraction that data pass through before being sent to a network device. When it comes to milliseconds, this can play a key role.
HTTP Pipelining
One can recall HTTP Pipelining, where client sends data using a single socket. You can check for yourself how it works with the netcat utility (you’ve got GNU/Linux, right?).
In fact, you better use Linux for many reasons: there is a more modern TCP/IP stack, which is supported by the operating system kernels. The server is most likely on Linux, as well.
For example, run nc google.com 80 command and insert the following lines there
GET / HTTP/1.1 Host: google.com GET / HTTP/1.1 Host: google.com GET / HTTP/1.1 Host: google.com
Thus, within one connection, three HTTP requests will be sent, and you will receive three HTTP responses. This feature can be used to minimize the time between requests.
What’s on the server side
The web server receives requests sequentially (this is the key point), and processes the responses in the same order. This peculiarity can be used to attack in several steps (when it is necessary to sequentially perform two actions in the minimum amount of time) or, for example, to slow down the server in the first request in order to increase the success of the attack.
Trick: You can prevent the server from processing your request by loading its DBMS, especially if INSERT/UPDATE is used. Heavier requests can “slow down” your load, thus, it will be more likely that you will win this race.
Splitting an HTTP Request Into Two Parts
First, let’s brush up on how the HTTP request is generated.
Well, as you know, the first line is the method, path, and the protocol version:
GET / HTTP/1.1
Next are the headers before the line break:
Host: google.com Cookie: a=1
But how does the web server know that the HTTP request has ended?
Let’s look at an example. Enter nc google.com 80, and there
GET / HTTP/1.1 Host: google.com
After you press ENTER, nothing will happen. Click again, and you will see the response.
That is, for the web server to accept the HTTP request, two line breaks are necessary. And the valid request looks like this:
GET / HTTP/1.1\r\nHost: google.com\r\n\r\n
If this were the POST method (don’t forget about Content-Length), then the correct HTTP request would be like this:
POST / HTTP/1.1 Host: google.com Content-Length: 3 a=1
Try sending a similar request from the command line:
echo -ne "GET / HTTP/1.1\r\nHost: google.com\r\n\r\n" | nc google.com 80
As a result, you will indeed get a response, since our HTTP request is complete. It won’t be the case, though, if you remove the last \n character.
In fact, many web servers just need to use \n as the line feed character, so it’s important not to swap \r and \n, otherwise further tricks may not work.
So, where does that leave us? You can simultaneously open many connections to a resource, send 99% of your HTTP request, and leave the last byte unsent. The server will wait until you send the last character, the line feed. Once it’s clear that the main part of the data has been sent, send the last byte (or several bytes).
This is especially important when it comes to a large POST request, for example, when a file upload is necessary. However, this makes sense even with small requests, since delivering a few bytes is much faster than simultaneously sending kilobytes of data.
Delay Before Sending the Second Part of the Request
According to the research of Vlad Roskov, you should not only split the request, but also make a delay of several seconds between sending the main part of the data and the final one. And all because web servers begin to parse requests even before they receive it completely.
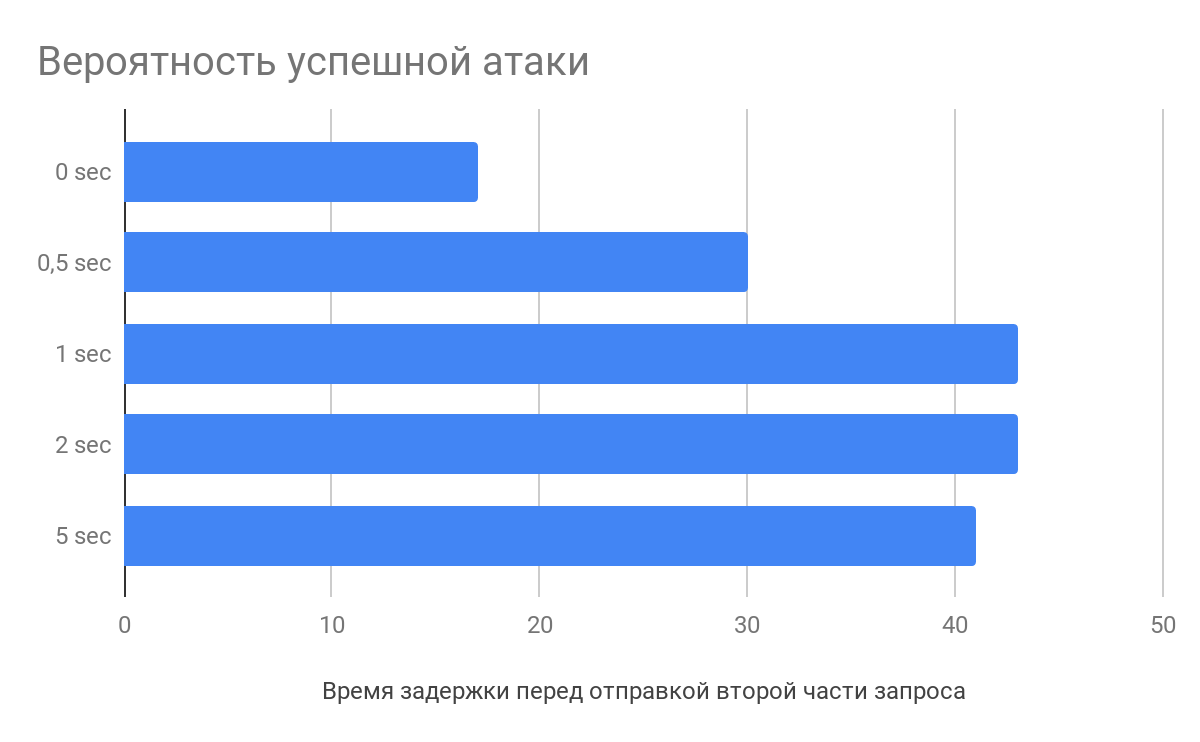
What’s on the server side
For example, when receiving HTTP request headers, nginx starts parsing them caching the incomplete request. When the last byte arrives, the web server will take the partially processed request and send it directly to the application, thereby reducing the processing time of requests, which increases the likelihood of an attack.
How to Deal With It
First of all, this is an architectural problem. If you properly design a web application, you can avoid such races.
Typically, the following attack prevention techniques are used:
- Locks.
The operation blocks the access to the locked object in the DBMS until it is unlocked. Others stand and wait on the sidelines. It is necessary to work with locks correctly, not to lock anything extra. - Isolations.
Serializable transactions ensure strictly sequential execution. This, however, can impact performance. - Mutual exclusions.
We use a tool like etcd to create an entry with a key at each function call. If it is not possible to create an entry, then it already exists and the request is interrupted. At the end of request processing, the entry is deleted.
I actually enjoyed the video by Ivan Rabotyaga about locks and transactions, it is very informative.
Session Capabilities in Race Condition
The session itself may prevent exploitation of the race condition. For example, in PHP, after session_start(), a session file is locked, and its unlocking occurs only at the end of the script (if there was no call of session_write_close). If another script that uses the session is called at this moment, it will wait.
To circumvent this capability, you can use a simple trick: to authenticate as many times as necessary. If the web application allows you to create many sessions for one user, just collect all the PHPSESSID and assign each request with its own ID.
Proximity to the Server
If the site you want to attack is hosted on AWS, rent a host on AWS. If the server is on DigitalOcean, rent it there.
When the task is to send requests and minimize the sending interval between them, immediate proximity to the web server will undoubtedly be a plus.
After all, it really makes a difference whether ping to the server is 200 ms or 10 ms. And if you’re lucky, you can even end up on the same physical server, then the exploitation will be a little easier.
The bottom line
There are various tricks you can use to increase the likelihood of a successful race condition. Send multiple keep-alive requests in one, slowing down the web server. Break the request into several parts and create a delay before sending. Reduce the distance to the server and the number of abstractions to the network interface.
As a result of this analysis, together with Michail Badin, we developed the RacePWN tool.
It consists of two components:
- C librace library, which sends a lot of HTTP requests to the server in the shortest time and using most of the tricks from the article.
- Racepwn utility, which gets json configuration and generally controls this library.
RacePWN can be integrated into other utilities (e.g., in Burp Suite), or you can create a web interface for managing races (I still can’t find time for this). Enjoy!
The truth is, there is still room for maneuver: we may recall HTTP/2 and its prospects for an attack. But at the moment, most resources have HTTP/2 only in the front end, proxying requests to the good old HTTP/1.1.
Maybe you have any other ideas?
alert(“хорошая шутка?)”)
Very informative piece. Mind if I share this with my team? It’s refreshingly honest.
Sometimes you stumble into the exact article you needed. This is one. All the best.
Well put together. Found it well explained. I honestly didn’t know half of this before. All the best.
Greetings, as someone who’s been in this space a while, Finally a post that respects the reader’s time. I couldn’t agree more.
Already sharing this with a couple of friends. If you ever do a newsletter, I’m first in line. Much appreciated.
Very informative piece. If more of the internet was written this way, we’d all be better off. Best,
Finally, someone gets it. Top-notch content.
Good day, truly appreciate the effort here. You nailed the nuances here. Thanks for sharing!
Awesome breakdown. My takeaway: you made a complex topic feel simple. Eager to read your next piece.
Awesome breakdown. Thank you for actually going deep on this. Stay awesome.
Been browsing similar content all week and this is the cleanest take. Bookmarked and subscribed.
Superb post. Rare to see such a structured post these days. Bookmarked and subscribed.
Very informative piece. Honestly refreshing to see a piece this extremely useful. Much appreciated.
Really enjoyed this. Do you cover the advanced angle anywhere?
Amazing article. Much respect for this piece.
Nice work on this one. What’s your go-to approach for this?
This was a wonderful read. Bookmarked and shared. I’ve been looking for something like this for a while. Thanks,
Clear, concise, and useful — a rare trifecta. Amazing article. Already following your blog.
Just wanted to drop a quick thanks — Finally a post that respects the reader’s time. Great work as always.
Hi there, truly appreciate the effort here. Great to see someone covering this properly. Take care.
Really enjoyed this. Sharing with a couple of colleagues who’ll find it clearly written. Cheers,
Good day! Really nice post. Saved me hours of digging around. Keep them coming!
Awesome breakdown. Will definitely revisit this when I start working on mine. Will definitely check back for updates.
Superb post. Sharing with a couple of colleagues who’ll find it refreshingly honest. Cheers,
Hey everyone, caught me at the right moment — Not often you find this level of depth online. Already following your blog.
Hello, truly appreciate the effort here. This cleared up a lot of confusion for me. Thanks again.
Top-notch content. If more of the internet was written this way, we’d all be better off.
Great article! Couple of these ideas I’ll be testing next week. Kudos to the author.
Hey all! Stumbled upon this and I’m glad I did. Nice work on this one.
Hello there, as someone who’s been in this space a while, You nailed the nuances here. My experience has been similar.
Fantastic post! You’ve gained a subscriber. Thanks for sharing!
Great article! Sharing with a couple of colleagues who’ll find it thorough and detailed. Best,
Hello there! Came for the title, staying for the craft. Take care.
Well put together. Genuinely helpful — not every day I can say that about online content. Bookmarked and subscribed.